eduMEET Lasttest mit Puppeteer - Bericht
Inhaltsverzeichnis
Einleitung und Zielsetzung
Motivation
Administratoren, die selbstgehostete VC-Instanzen ihr eigen nennen dürfen (oder es irgendwann einmal möchten), stehen oftmals vor der Frage: "Wie viele gleichzeitige Nutzer hält unser Setup eigentlich Stand bevor es in die Knie geht?" bzw. "Wie groß muss die Instanz dimensioniert werden, sodass ein reibungsloser Betrieb gewährleistet ist?".
Zielsetzung
Ideal wäre es natürlich, diese Information zu haben bevor es zu verärgerter Nutzerschaft kommt. Um an die Antworten auf diese Fragen zu kommen, bedarf es eines Prozesses, welche die verschiedenen Faktoren wie Anzahl der Teilnehmer, konfigurierte Instanz, infrastrukturelle Begebenheiten usw. berücksichtigt und schlussendlich zu einem Ergebnis kommt und die Fragen aus der Motivation beantwortet.
Da es viele menschliche Ressourcen binden würde, Lasttests mit realen Endgeräten durchzuführen, gibt es Möglichkeiten, das Ganze zwar synthetisch aber möglichst realitätsnah zu realisieren. Das VCC hat sich eine dieser Möglichkeiten herausgenommen und einen Lasttest mit der Javascript Bibliothek Puppeteer durchgeführt.
Szenario
Je länger man sich mit dem Thema Lasttest auseinandersetzt, desto tiefer gräbt man sich in das Kaninchenloch hinein. Um nicht dem nervigen Problem des Scope Creeps zu verfallen, bei dem man während der Durchführung eines Projekts denkt "man könnte ja gleich noch Aspekt x und y betrachten", empfiehlt es sich, sehr genau abzustecken was man testen möchte und in welchem Szenario.
Einige Fragen, die man sich dabei stellen sollte sind:
- Welchen Zweck soll mein Lasttest verfolgen? Systemstabilität gewährleisten? Maximale Benutzeranzahl pro Instanz? Benutzerqualität evaluieren?
- Soll eine Hardware-Evaluation stattfinden oder bestehende Systeme auf Zukunftssicherheit geprüft werden?
- Aus welcher Sicht soll getestet werden? Benutzer oder Systemadministrator? Aus Sicht der Infrastruktur?
Abgrenzung
Zur Reduktion der Systemkomplexität wurden vereinfachende Annahmen getroffen. Diese sind notwendig, um einzelne Einflussfaktoren isoliert zu betrachten und reproduzierbare Messergebnisse zu erzielen. Die Ergebnisse sind innerhalb des beschriebenen Szenarios gültig; abweichende Annahmen können zu veränderten Resultaten führen und bilden Ansatzpunkte für weiterführende Untersuchungen.
Um einen sehr abgesteckten Testrahmen zu haben, wurden daher folgende Abgrenzungen getroffen:
- Minimal Instanz→ "Wie minimal darf meine Instanz sein, sodass sie trotzdem noch einen Service erbringen kann?"
- eduMEET als beispielhaftes Videokonferenzsystem, welches aus Quelloffenheits- und Schlankheitsgründen gewählt wurde.
- Es findet kein Feature- oder Versionsvergleich statt, es wird ausschliesslich eine Version getestet
- Szenario: ein Meetingraum, alle Personen senden und Empfangen alle Video- und Audiostreams
Annahmen
Getroffene Annahmen lauten:
- Der Flaschenhals, welcher zum Ausfall oder der Beeinträchtigung des Dienstes führt, erzeugt reproduzierbar das gleiche Fehlerbild unabhängig davon wie groß der Teil der Instanz dimensioniert ist, der dafür zuständig ist. Konkret ist damit gemeint, dass es für den Benutzer bzw. das Fehlerbild keine Rolle spielt, ob die VM mit 4GB RAM vollläuft oder mit 64GB. Analog ist das Fehlerbild identisch, wenn ein CPU-Kern überlastet bzw. gesättigt ist, oder alle 64 Kerne.
- GUI-lose Teilnehmer, welche aus dem Puppeteer-Skript erzeugt wurden (und damit synthetisch sind), erhalten in allen Belangen das gleiche Bild wie der Monitor-Teilnehmer, welcher nicht synthetisch erzeugt wurde.
Sollten Sie einen solchen Test selbst planen oder generell Interesse am Thema Lasttest haben, so empfiehlt es sich unsere Kurzanleitung zu diesem Thema zu lesen.
Testumgebung
Die VM, gegen die getestet wurde, besaß einen 1 Kern-CPU mit 1GB Arbeitsspeicher. Ein laufendes System mit Betriebssystem hat bereits eine RAM-Belegung von über 600 MB, daher kam eine VM mit 512 MB RAM nicht in Frage. Die 600 MB beinhalten allerdings auch die Arbeitspeicherbelegung des Betriebssystems selbst, somit kann mit weniger ressourcenhungrigen Betriebssystemen (wie bspw. OpenWRT) eine sub-1GB-RAM-Instanz möglich sein, siehe Ausblick.
Die lasterzeugende Instanz verwendete einen 48 Kern-CPU mit 96 GB RAM.
Testmethodik
Das erzeugen von Last realisiert Puppeteer.
Puppeteer ist laut der offiziellen Webseite pptr.dev eine Javascript Bibliothek, welche eine High-Level API zur Kontrolle von Chrome oder Firefox bereitstellt. Standardmäßig läuft Puppeteer headless, das heisst ohne graphisches User Interface. Puppeteer ist also keine reine Stresstest-Suite, sondern vielmehr ein Schweizer Taschenmesser der GUI-losen Browsersteuerung. Welche Zielsetzung man mit dem Tool verfolgt, ist zunächst einmal offen.
In unserem Fall begegneten wir dem Stresstest mit Puppeteer programmatisch mit einem Script, welches verschiedene Nutzerinteraktionen simuliert. In Kürze sind das die folgenden Dinge:
- Nutzer betreten Videokonferenzraum,
- senden dauerhaft Video/Audio und
- erzeugen somit Last für die zu testende Instanz
Das Skript dazu sieht so aus (einen Link zum Github Repository finden Sie am Ende dieser Seite):
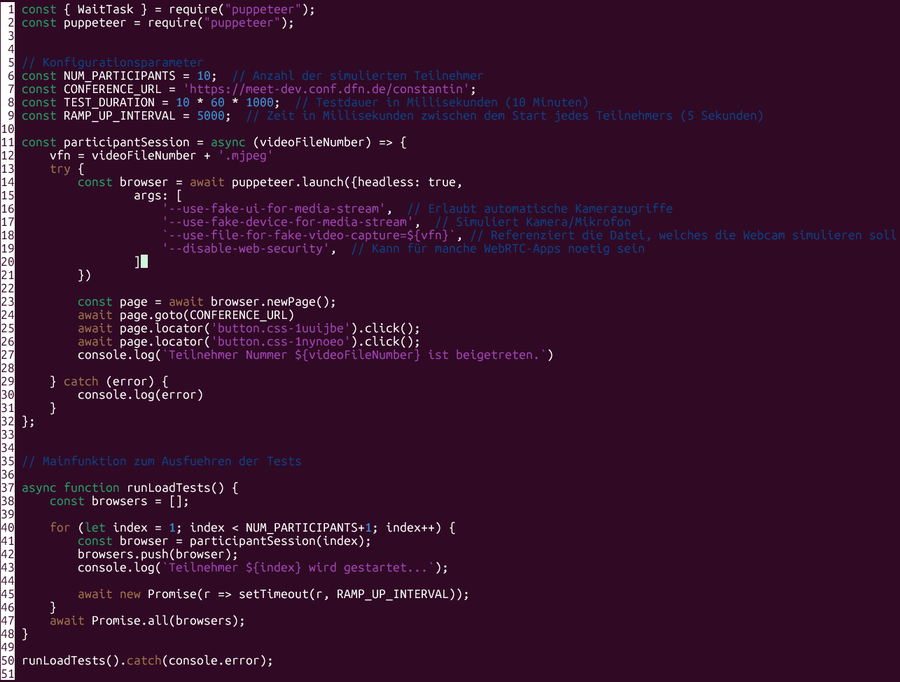
eduMEET Mutlijoin.js
Nähere Erläuterungen dazu finden Sie in der Anleitung.
Runtergebrochen passiert das folgende:
- Importiere die Bibliothek
- Spezifiziere Parameter wie Konferenz-URL, Testlänge, Intervall etc.
- Starte eine(n) Browser(instanz) mit etlichen Parametern (Fake-Videostream etc.)
- Öffne einen neuen Tab
- Gehe auf die Seite, die man testen möchte
- Gehe die einzelnen Schritte durch, die ein Benutzer auch durchgehen müsste (Konferenzbeitreten klicken)
Die Funktion runLoadTests() setzt die Schleifenlogik um, sorgt also dafür dass mehrere Browserinstanzen gestartet werden und dass jede Browserinstanz das gleiche macht.
Wenn man das Skript startet, wird alle 5 Sekunden ein neuer Teilnehmer mit Video in eine Meeting geschickt und erzeugt fortan Last.
Daraus ergibt sich der Ablauf des Tests wie folgt:
Befülle ein Meetingraum so lange mit Video und Audio sendenden Teilnehmern, bis die VM in die Knie geht und Ausfallerscheinungen auftreten.
Ergebnisse
In unserem Test hat ein System mit einem CPU Kern und einem Gigabyte RAM ab dem Beitritt eines 28. Teilnehmer aufgehört normal bzw. erwartungsgemäß zu arbeiten:
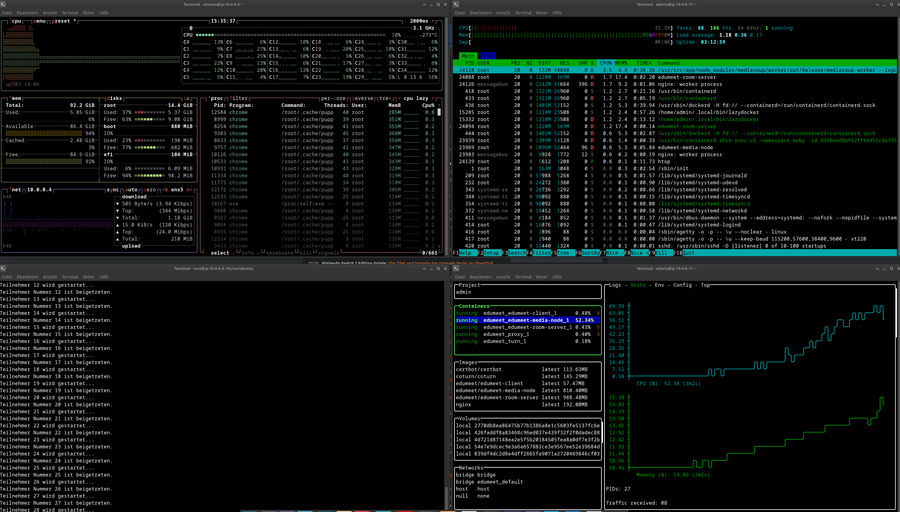
Die beiden rechten Terminals spiegeln den Zustand der getesteten Instanz wider. Während der CPU noch vergleichsweise wenig Arbeit verrichtet, ist der RAM komplett vollgelaufen. Das System wurde indes vollständig unresponsiv, sowohl auf Seiten der Teilnehmer als auch auf der Seite des Administrators (also per Terminal und SSH). Teilnehmer im Meeting Raum erhielten abrupt weder Ton noch Audio der anderen Teilnehmer und konnten auch keinen Button mehr klicken bzw. es hatte keine Wirkung.
Somit ist festzuhalten: Ein System mit den folgenden Spezifikationen und Szenariobedingungen:
- 1 Kern CPU
- 1 GB RAM (kein SWAP)
- Debian 12 Bookworm OS
- laufender eduMEET Container
- einzelner Raum, alle Teilnehmer senden Video und Audio
... kann 27 Teilnehmern in einer Videokonferenz beherbergen. Der 28. Teilnehmer führt zur Beanspruchung zu vieler Ressourcen im Zwischenspeicher der Instanz, woraufhin diese unresponsiv wird.
Bis zum 28. Teilnehmer sind keine vorherigen Ausfallerscheinungen aufgetreten.
Analyse und Interpretation
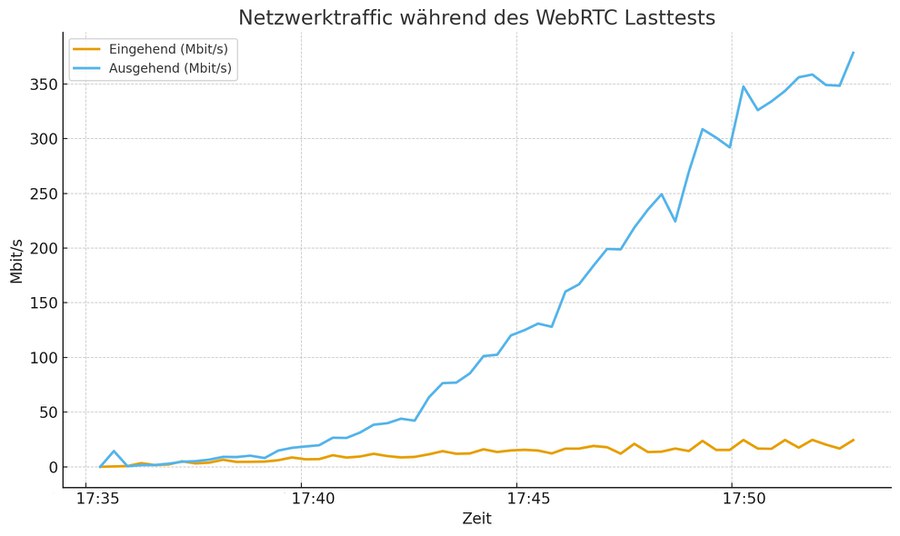
Das Logging der anschließend analysierten und interpretierten Daten wurde wie folgt durchgeführt: Für den CPU wurde die momentane Last des gesamten Systems gemessen und in eine .csv-Datei geschrieben. Aus dieser Datei geht folgender Graph hervor:
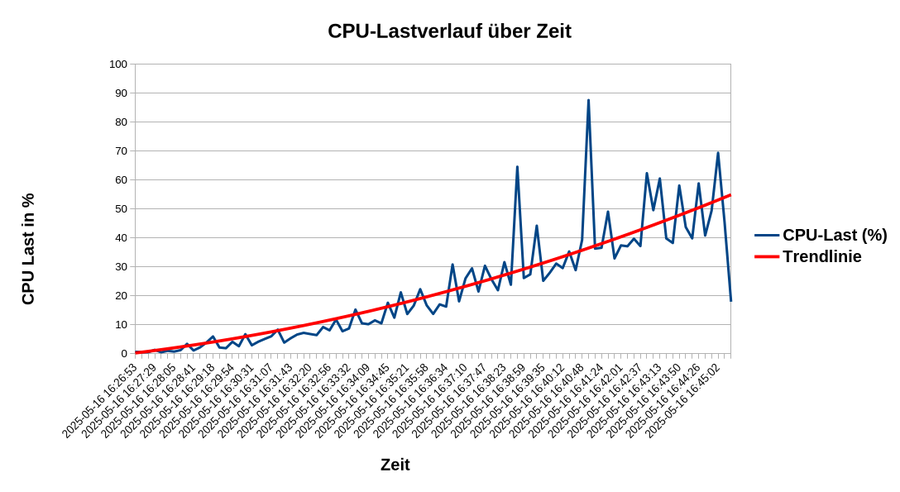
Trotz des großzügig gewählten Aufnahmeintervalls, um verfälschende Lastspitzen abzufangen, kam es zu etlichen Ausreissern mit fast 90% CPU Last. Der allgemeine Trend wirkt auf den ersten Blick recht stabil im Sinne von linear. Auf den zweiten Blick erkennt man allerdings, dass die erste Hälfte des Graphs unter der Trendlinie, der zweite Teil des Graphen zunehmend über der Trendlinie verläuft. Das lässt darauf schließen, dass es sich hier nicht um einen linearen Anstieg der CPU Last handelt.
Für die Zwischenspeicherbelegung gilt das gleiche Intervall wie für den CPU-Chart, allerdings wurde hierbei nur die RAM-Belegung des Docker Containers berücksichtigt, nicht des gesamten Systems. Daraus ergibt sich auch, warum die VM unresponsiv geworden ist bei ~350 MB RAM-Belegung: Wie eingangs erwähnt wurde als Betriebssystem Debian verwendet, welches im Idle bereits etwas ueber 600 MB RAM benötigt. Da die VM lediglich 1GB Arbeitsspeicher besitzt, ist dieser bei den grob 350 gemessenen Megabyte voll.
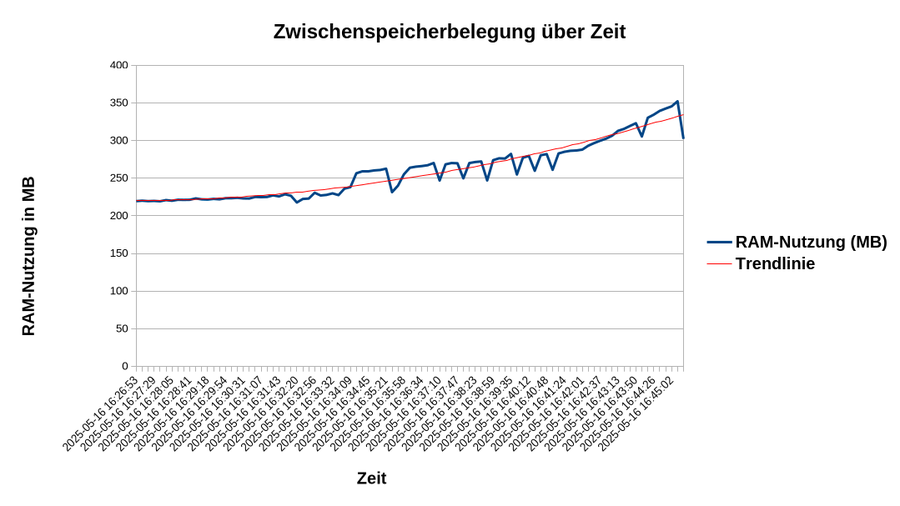
Auch hier ist die Beobachtung ähnlich zur CPU-Lastentwicklung: bei geringen Teilnehmerzahlen im Meeting steigt die RAM Nutzung nahezu nicht an und ab der zweiten Hälfte des Tests steigt die Arbeitsspeicherbelegung sprungartig an. Gegen Ende des Tests ist außerdem ein stärkerer Anstieg zu verzeichnen, als es im mittleren Teil der Fall war.
Das lässt den Schluss zu, dass auch der Speicherverbrauch nicht linear ansteigt sondern stärker. Dies ist durch die nach oben gebogene Trendlinie ebensfalls ersichtlich.
Warum der Docker Container jedoch in der Mitte des Tests einige Male Speicher freigibt, entzieht sich unserem Verständnis.
Limitationen/potenzielle Fallstricke
Wenn man die zu testende Instanz etwas größer dimensioniert als in der oben beschriebenem Minimalkonfiguration, so ergeben sich recht schnell einige Probleme:
Da sich in dem gewählten Szenario alle Teilnehmer in einem Raum befinden, müssen auch alle Teilnehmer die Video- und Audiostreams der anderen Teilnehmer erhalten. Das hat zur Folge, dass jeder Teilnehmer (lies: jede per Puppeteer gestartete Browserinstanz) auch jeden einzelnen Mediastream dekodieren muss. Die CPU Last steigt damit (fast) quadratisch, denn für jeden neuen Teilnehmer entstehen n-1 neue Streams die dekodiert werden müssen:
- 1 Client = 0x dekodieren
- 2 Clients = 2*1 dekodieren
- [...]
- 5 Clients = 5*4 = 20x dekodieren
- 30 Clients = 30*29 = 870x dekodieren
- etc.
Das erzeugt sehr schnell, sehr viel CPU Last auf der lasterzeugenden VM, welche dadurch viel schneller gesättigt wird, als die zu testende Instanz:
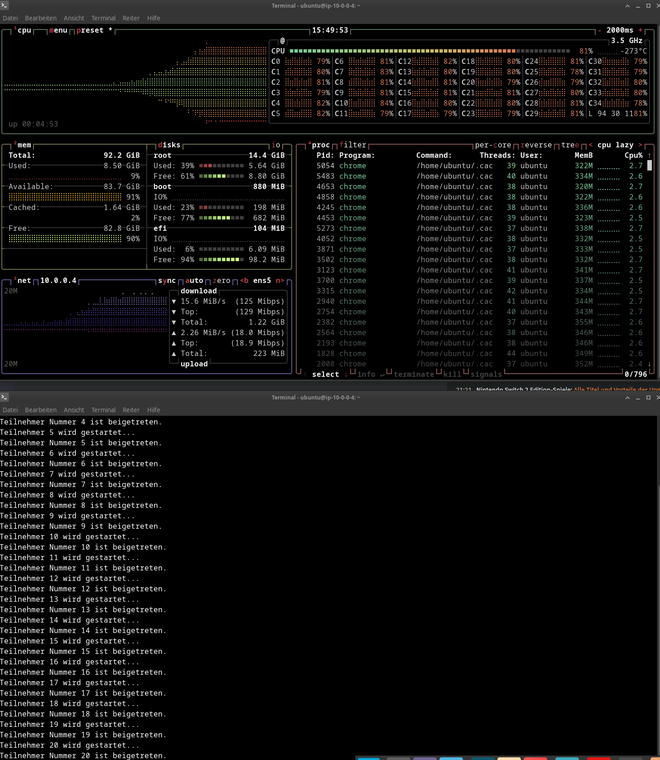
Das obige Bild zeigt die Auslastung der lasterzeugenden VM bei 20 Teilnehmer. Die lastempfangende VM, also die zu testende Instanz hingegen hat einer Auslastung von unter 5%.
Aus der Sicht der zu testenden VC-Instanz ist es aber nicht notwendig, alle reinkommenden Mediastreams zu dekodieren, da man die Browserinstanz ja headless - also ohne GUI - startet und die VC-Qualität über einen separaten Monitoring-PC prüft. Allerdings kann man den Browser nicht zum Kooperieren zwingen und ihm befehlen, er solle einfach den WebRTC Stream nicht dekodieren. Keine der verfügbaren Browser-Flags haben es geschafft, die Dekodierung der Mediastreams auf Browserebene zu unterbinden (siehe dazu den den Abschnitt "Offene Punkte" der Kurzanleitung).
Fazit
Puppeteer als Lasttestumgebung zu wählen stellt sich im Nachhinein als suboptimal heraus. Prinzipiell ist die Herangehensweise möglich und kann mit genügend Hardwarepower auch durchgeführt werden, allerdings sind durch mehrere Begebenheiten (Trafficaufkommen, erzwungene Dekodierung der synthetischen Teilnehmer, Verwehrung der Auslagerung des En- und Dekodierungsprozesses auf verbaute GPUs) nur eine sehr begrenzt große Konfigurationen testbar.
Zwar bringt Puppeteer diverse Vorteile wie Flexibilität und VC-agnostische Verwendbarkeit mit sich, leider werden diese überschattet von den Limitationen, welche mit den leider gerade nicht so flexibel anwendbaren Browserflags einhergehen.
Die festgestellten Ausfallerscheinungen waren das komplette Einfrieren der Videokonferenz, hervorgerufen durch das Sättigen des Arbeitsspeichers; die Latenzerhöhung von Ton und Bild durch das Sättigen des CPUs. Aus Sicht der Selbstheilung bzw. Fehlerbehebung ist beim Volllaufen des RAMs keinerlei Möglichkeit gegeben eine Videokonferenz weiterzuführen ohne die VM nicht komplett neuzubooten. Für den Fall dass nur die CPUs ausgelastet sind, verschwinden die Ausfallerscheinungen wieder, wenn die Last sinkt und es kann weiterhin konferiert werden.
Desweiteren war die Wahl des Betriebssystems für die Instanz nicht ideal gewählt. Betriebssysteme mit kleinerem Arbeitsspeicherbedarf wie OpenWRT könnten die Anforderungen an eine Minimalinstanz nochmal von 1 GB auf einen Wert darunter verbessern.
Ausblick & Future Work
Das skizzierte Szenario ist wohl aus vielerlei Gründen synthetisch und nicht realitätsnah. Zum einen kommt es wohl vergleichsweise selten im Videokonferenz-Usus vor, dass alle Teilnehmer gleichzeitig Video und Audio senden (und auch empfangen wollen), zum anderen verteilt sich die Last eher über mehrere Räume als sich in einem einzigen Raum zu konzentrieren. Natürlich gibt es Ausnahmen, wie beispielsweise Einführungsveranstaltungen an Universitäten oder gut besuchte Podiumsdiskussionen mit vielen interaktionswilligen Teilnehmern.
Die Anzahl der zu betrachtenden Dimensionen geht recht schnell weiter auf und bedarf gesondert Aufmerksamkeit bzw. kann in zukünftigen Arbeiten aufgegriffen werden. Somit kann sich die weitere Forschung mit der Frage beschäftigen, wie sich eine eduMEET Instanz verhält, wenn lediglich eine Person in einem Raum Audio und Video sendet und es sozusagen nur konsumierende Teilnehmer des Video und Audiostreams gibt. Das entspräche in etwa dem Szenario "Streaming".
Ein anderes denkbares Testszenario wäre jeweils zwei Teilnehmer pro Meeting, jedoch sehr viele unterschiedliche Räume zu instanziieren. Damit würde man mehr die Performance der Raum Management Komponente von eduMEET überprüfen als die Performance der darunterliegenden WebRTC-Engine.
Ferner erscheint es sinnvoll sich dem starken Overheads der Methodik durch Puppeteer zu entledigen. Das kann in einem Lasttest sinnvoll sein, der konkrete laufende Instanzen überprüfen möchte und deren Breaking Point. Auf Github gibt es ein Repository, welches mit Python ein schlankeres Tool zum Lasttesten bereithält. Allerdings ist dieses Tool in einem sehr frühen Stadium der Entwicklung und eher ein Proof-of-Concept als eine vollwertige Suite. Nichtsdestotrotz sollte es möglich sein, mit diesem Tool ein weiter Fragestellung zu klären: Skaliert eduMEET (nahezu) linear pro Teilnehmer? Wie lautet der Faktor, der beschreibt wie stark die Last ansteigt für jeden zusätzlichen Teilnehmer? Damit geht man außerdem der Frage nach, ob sich die Ergebnisse der Kleinstinstanz auf eine große Instanz übertragen lassen.