Ausgewählte Forschungsfelder
Einblicke in die Professur für Sprachtechnologie und Kognitive Systeme
ARTIKULATORISCHE SPRACHSYNTHESE
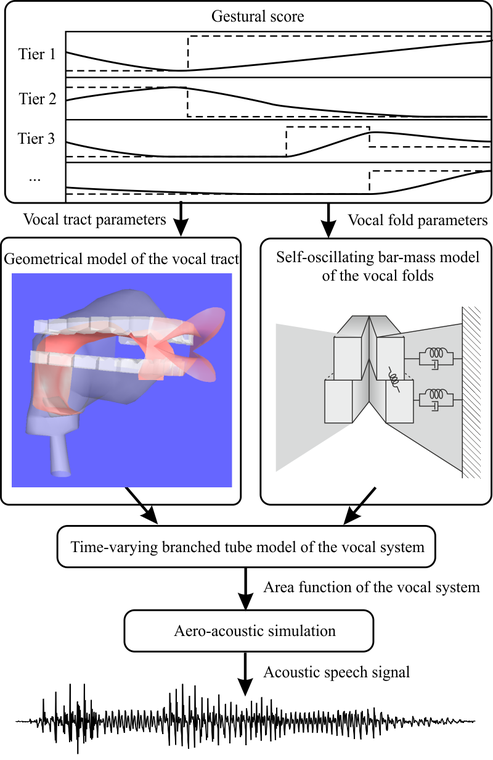
Artikulatorische Sprachsynthese bezeichnet die Synthese von Sprache auf der Basis einer artikulatorischen und aeroakustischen Simulation des menschlichen Sprechapparats. Diese Art der Sprachsynthese ist gänzlich anders als die etablierten Synthesetechnologien. Derzeitige Systeme basieren meistens auf der Verknüpfung kurzer Einheiten (z. B. Silben oder Diphone) oder aufgenommener natürlicher Sprache. Die besten dieser Systeme können eine halbwegs natürlich klingende Sprache erzeugen. Trotzdem ist Ihre Flexibilität, bedingt durch die Nutzung aufgenommenen natürlichen Sprachmaterials, im Hinblick auf die Erzeugung unterschiedlicher Stimmen, Sprachstile, Emotionen usw. ziemlich eingeschränkt.
Das Ziel unserer Forschung ist es, diese Beschränkung durch eine effektive Simulation der menschlichen Spracherzeugung zu überwinden. Dafür entwickeln und verbinden wir Modelle des Vokaltrakts, der Stimmlippen, der Strömungsakustik und der artikulatorischen Ansteuerung. Die Herausforderung dabei besteht darin, Modelle zu entwickeln, die so detailliert wie nötig sind, um alle relevanten Phänomene der Spracherzeugung zu simulieren, und dabei so einfach wie möglich, um mit derzeitigen Sprachsyntheseanwendungen kompatibel zu sein. Im Gegensatz zur derzeitigen Sprachsynthesetechnologie profitiert unsere Arbeit sehr von der Grundlagenforschung der Phonetik. Mittelfristig wird die artikulatorische Synthese möglicherweise die Methode sein, einen sehr natürlichen Klang und eine ausdrucksstarke und konfigurierbare Sprachsynthese zu erzeugen. Weiterhin liefert sie u.a. neue Möglichkeiten für die Analyse und Synthese von Gesang, für die Didaktik und für die phonetische Forschung.
Für mehr Informationen zur artikulatorischen Sprachsynthese siehe www.vocaltractlab.de
Neue apparative Verfahren für die Sprachforschung
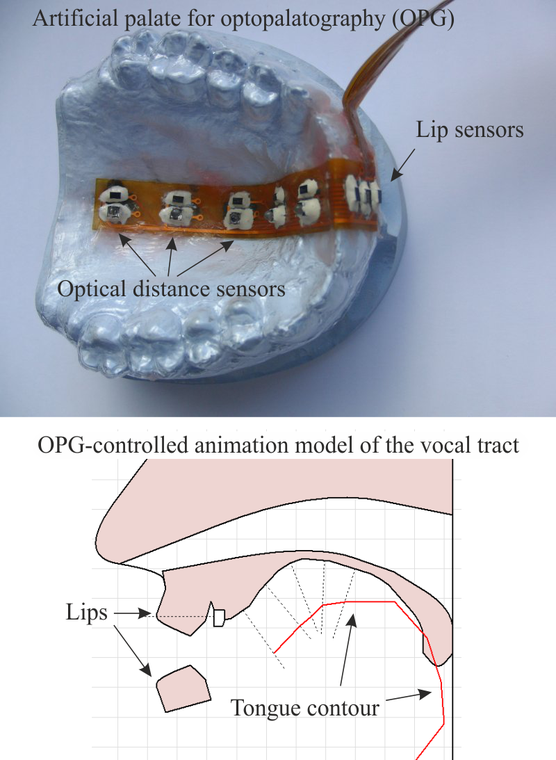
Wir entwickeln neue Techniken um unterschiedliche Gesichtspunkte der Sprachproduktion zu erfassen. Eine dieser Techniken ist die elektrooptische Stomatographie, bei der die Zungen- und Lippenbewegungen während des Sprechens gemessen werden. Dafür wird einem Sprecher eine künstliche Gaumenplatte an seinen Gaumen angepasst, die mit optischen Entfernungssensoren und elektrischen Kontaktsensoren bestückt ist. Diese Sensoren erlauben die Rekonstruktion des mittigen Sagittalschnitts der Zunge und der Lippenstellung mit einer Abtastrate von 100 Hz. Diese Technik kann in der phonetischen Grundlagenforschung, in der Erkennung stiller Sprache („Silent Speech Interfaces“) oder als visuelles artikulatorisches Feedback für die Sprachtherapie, das Fremdsprachenlernen oder die Lehre angewendet werden.
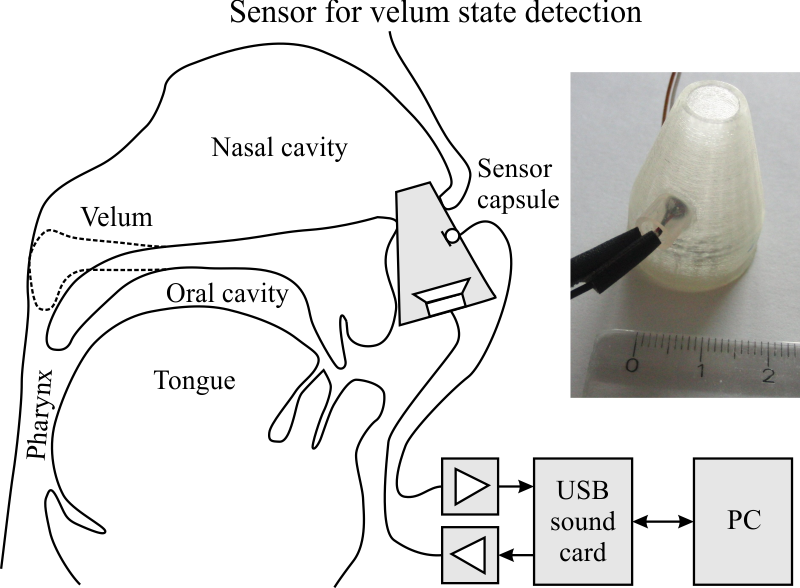
Weiterhin entwickeln wir ein neuartiges Messverfahren zur Verfolgung der Stellung des Gaumensegels (Velum). Diese Technik basiert auf einer Sensorkapsel, die einen Miniaturlautsprecher und ein Miniaturmikrofon enthält und vom Nutzer in ein Nasenloch gesteckt wird. Der Lautsprecher sendet sog. akustische Chirps mit einem Leistungsband zwischen 12 und 24 kHz in die Nasenhöhle, während das Mikrofon die "gefilterten" Chirps aufnimmt. Da sich die Filtereigenschaften der Nasenhöhle zwischen einem angehobenen und abgesenkten Gaumensegel unterscheiden, kann der aktuelle Zustand aus dem Spektrum des gefilterten Eingangssignals abgeleitet werden. Da das Messsystem akustische Frequenzen jenseits von 12 kHz verwendet, stört es die normale Sprachproduktion nicht. Daher funktioniert das System sowohl während still artikulierter als auch normal gesprochener Sprache.
Spracherkennung mit rekurrenten neuronalen Netzen
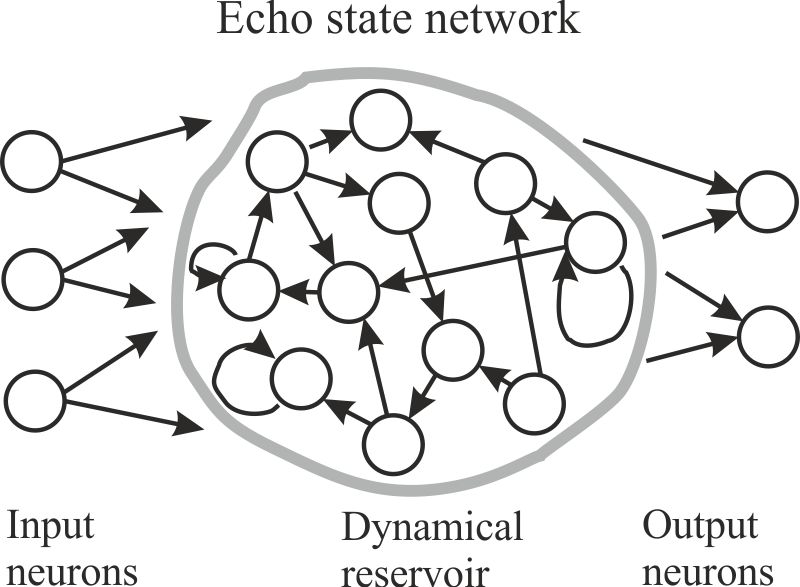
In den letzten Jahren gab es gewaltige Fortschritte im Verständnis der Verarbeitung von Informationen durch das menschliche Gehirn. Einige dieser neuen Erkenntnisse wurden in neue Methoden des Maschinellen Lernens, wie Echo State Networks, Liquid State Machines oder Deep Belief Networks übernommen. In dieser Forschungslinie wollen wir diese Methoden weiterentwickeln und sie auf dem Gebiet der Sprachverarbeitung nutzen.