Research Areas
Einblicke in die Professur für Sprachtechnologie und Kognitive Systeme
ARTIKULATORY SPEECH SYNTHESIS
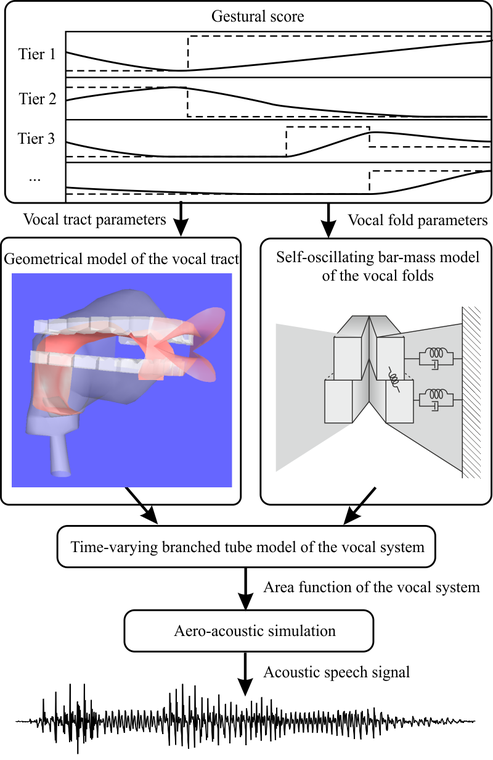
Articulatory speech synthesis denotes the synthesis of speech based on an articulatory and aero-acoustic simulation of the vocal system. This way of speech synthesis is completely different from current established synthesis technology. Current systems are mostly based on the concatenation of short units (for example, syllables or diphones) of recorded natural speech. The best of these systems are now able to generate quite natural sounding speech. However, due to their use of recorded natural speech material, their flexibility is rather limited with regard to the generation of different voices, speaking styles, emotions, etc. The goal of this line of research is to overcome these limitations with an actual simulation of human speech production. Therefore, we develop and combine models of the vocal tract, the vocal folds, aero-acoustics, and articulatory control. The challenge here is to make these models as detailed as necessary to simulate all the phenomena relevant for speech production, but keep them as simple as possible to be applicable for actual speech synthesis applications. In contrast to current speech synthesis technology, our work here greatly benefits from basic phonetic research. In the middle-term, articulatory synthesis may be the way to generate highly natural sounding, expressive and configurable speech synthesis. Furthermore, it provides, amongst others, new possibilities for the analysis and synthesis of singing, didactics, and phonetic research. More information about our articulatory synthesizer project can be found at www.vocaltractlab.de.
MEASUREMENT TECHNIQUES FOR SPEECH RESEARCH
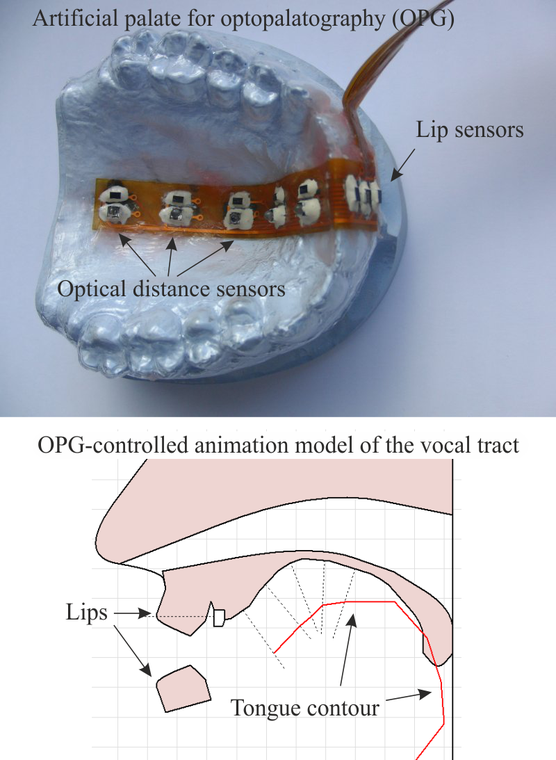
In this line of research we develop new techniques to measure different aspects of speech production. One of these techniques is optopalatography (OPG) to measure tongue and lip movements during speaking. Therefore, the speaker wears an artificial palate fitted to his hard palate, which is equipped with optical distance sensors. Our current artificial palates employ five sensors along the palatal midline directed towards the tongue, and two sensors in front of the upper incisors directed towards the upper lip. These sensors allow reconstructing the mid-sagittal shape of the tongue and the state of the lips with a frame rate of 100 Hz. This technique can be applied in basic phonetic research, in “silent speech interfaces”, or for providing visual articulatory feedback for speech therapy, foreign language learning, or education.
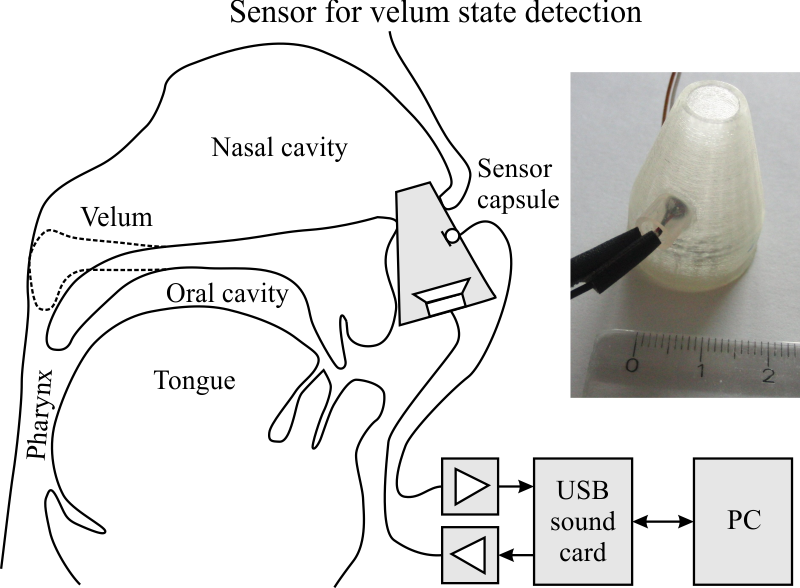
We also develop a new measurement technique to track the state of the velum. This technique is based on a sensor capsule containing a miniature loudspeaker and a miniature microphone that the user plugs in one nostril. The loudspeaker periodically emits acoustic chirps with a power band between 12 and 24 kHz into the nasal cavity, and the microphone measures the “filtered” chirps. Since the filter characteristics of the nasal cavity differ between a high and low velum state, the state can be inferred from the spectrum of the filtered source signal. Since the measurement system uses acoustic frequencies above 12 kHz, it does not interfere with normal speech production. Therefore, the system works both during silent and normal speaking.
ARTIFICAL NEURAL NETWORKS FOR SPEECH SYNTHESIS AND SPEECH RECOGNITION
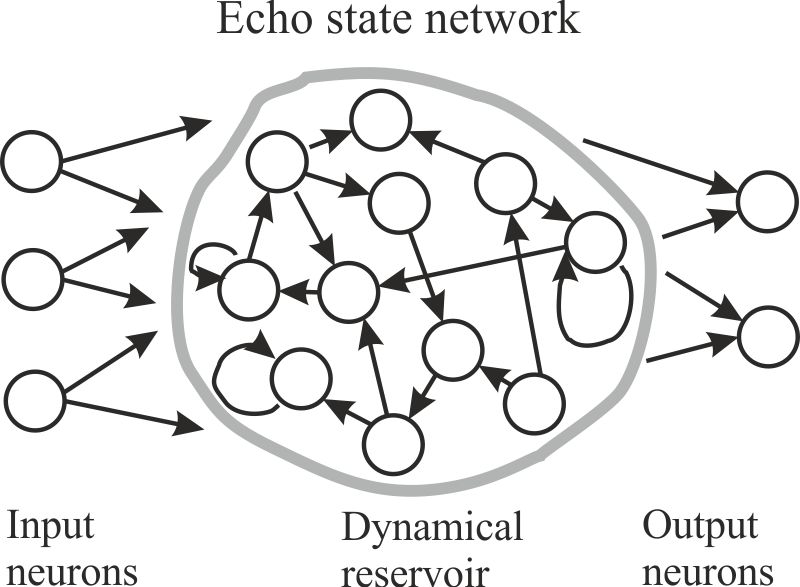
In the last years there has been tremendous progress in the understanding of how the human brain processes information. Some of the new findings have already been translated into new machine learning methods like Echo State Networks, Liquid State Machines, or Deep Belief Networks. In this line of research we intend to develop these methods further and exploit their potential in the field of speech and language processing.