Aug 13, 2019
Mathematicians of TU Dresden develop new statistical indicator

Most of us know this phenomenon only too well: as soon as it is hot outside, you get an appetite for a cooling ice cream. But would you have thought that mathematics could be involved?
Let us explain: The rising temperatures and the rising ice consumption are two statistical variables in linear dependence; they are correlated.
In statistics, correlations are important for predicting the future behaviour of variables. Such scientific forecasts are frequently requested by the media, be it for football or election results.
To measure linear dependence, scientists use the so-called correlation coefficient, which was first introduced by the British natural scientist Sir Francis Galton (1822-1911) in the 1870s. Shortly afterwards, the mathematician Karl Pearson provided a formal mathematical justification for the correlation coefficient. Therefore, mathematicians also speak of the “Pearson product-moment correlation” or the “Pearson correlation”.
If, however, the dependence between the variables is non-linear, the correlation coefficient is no longer a suitable measure for their dependence.
René Schilling, Professor of Probability at TU Dresden, emphasises: "Up to now, it has taken a great deal of computational effort to detect dependencies between more than two high-dimensional variables, in particular when complicated non-linear relationships are involved. We have now found an efficient and practical solution to this problem."
Dr. Björn Böttcher, Prof. Martin Keller-Ressel and Prof. René Schilling from TU Dresden’s Institute of Mathematical Stochastics have developed a dependence measure called "distance multivariance". The definition of this new measure and the underlying mathematical theory were published in the leading international journal "Annals of Statistics" under the title "Distance Multivariance: New Dependence Measures for Random Vectors".
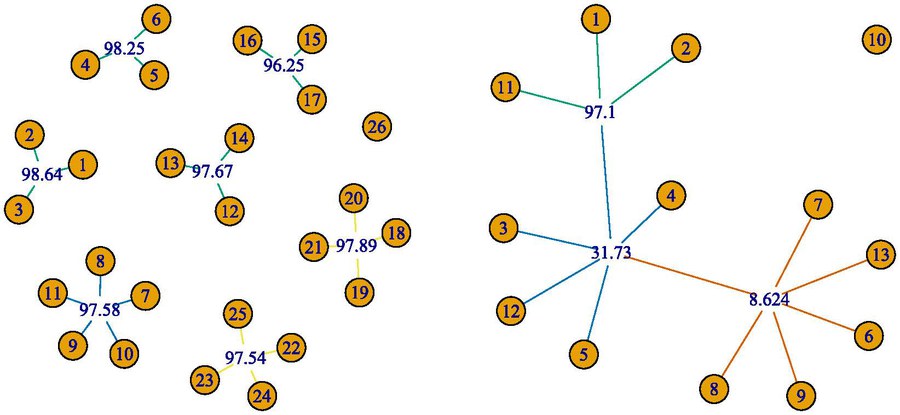
Examples of complex dependency structures, which could be reconstructed using distance multivariance.
Martin Keller-Ressel explains: "To calculate the dependence measure, not only the values of the observed variables themselves, but also their mutual distances are recorded and from these distance matrices, the distance multivariance is calculated. This intermediate step allows for the detection of complex dependencies, which the usual correlation coefficient would simply ignore. Our method can be applied to questions in bioinformatics, where big data sets need to be analysed."
In a follow-up study, it was shown that the classical correlation coefficient and other known dependence measures can be regained as borderline cases from the distance multivariance.
Björn Böttcher concludes by pointing out: „We provide all necessary functions in the package 'multivariance' for the free statistics software 'R', so that all interested parties can test the application of the new dependence measure".
Original publication:
B. Böttcher, M. Keller-Ressel, R. Schilling, Distance multivariance: New dependence measures for random vectors, Annals of Statistics 2019, Vol. 47, No. 5, 2757-2789.
Media contact:
Prof. Martin Keller-Ressel
Tel. 0351 463 35234
E-Mail: