14.10.2024
The Perks and Perils of Machine Learning in Business and Economic Research: Neues Arbeitspapier zum Einsatz von Machine Learning in der wirtschaftswissenschaftlichen Forschung

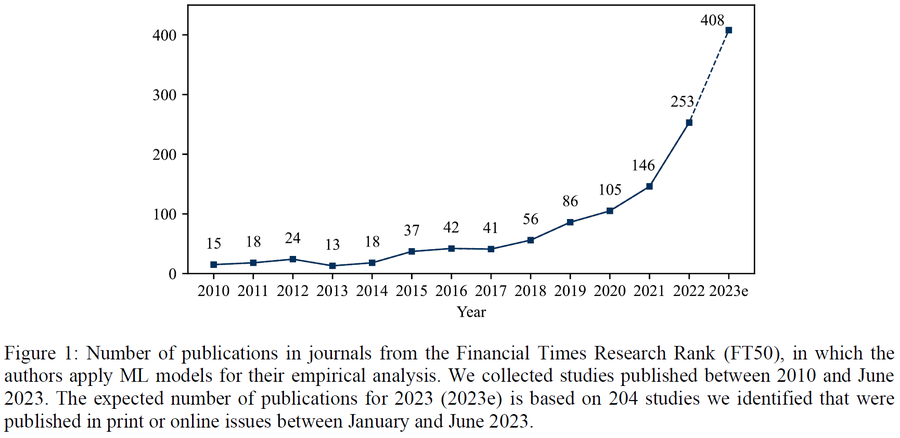
Am 10.10. hat Prof. Lars Hornuf ein neues Arbeitspapier an der wirtschaftswissenschaftlichen Fakultät der KU Leuven in Belgien vorgestellt. Das Arbeitspapier ist unter dem folgenden Link zugänglich: SSRN. Für das Papier haben sich Tom Dudda und Prof. Hornuf mehr als 50.000 Papiere aus den FT50 Journals angeschaut und sich die folgenden Fragen gestellt:
(1) Wie viel Forschung wird in verschiedensten Disziplinen der Wirtschaftswissenschaften unter Anwendung von Machine Learning (ML) Modellen publiziert?
- Für den Zeitraum zwischen 2010 und Q2 2023 wurden 1.058 Papiere in den FT50 Journals identifiziert, in welchen ML Methoden zur Anwendung kommen. In 223 Studien werden ML Modelle genutzt, um damit eine prädiktive Forschungsfrage zu beantworten, wie z.B. die Vorhersage von Aktienkursen, Kundenverhalten oder Betrug.
- ML wird am häufigsten in Publikationen in Journals aus den folgenden Disziplinen verwendet: Information Systems, Marketing, Operations Research/Management
- Gemessen am Anteil aller Publikationen einer Fachrichtung wird ML in den folgenden Disziplinen bedeutend seltener eingesetzt: Human Relations, Organization, Economics, Accounting
(2) Gegenüber traditionellen statistischen Methoden, wie beispielsweise linearen oder logistischen Regressionen, erfordern ML Modelle häufig einen bedeutend höheren Ressourcenverbrauch (Zeit, Energie, Emissionen) sowie den Verlust von der Interpretierbarkeit bzw. Erklärbarkeit der Ergebnisse. Die erhöhten Modellkosten sind nur zu rechtfertigen, wenn die Verbesserungen der Vorhersagemodelle ökonomisch so signifikant sind, dass sie die höheren Modellkosten übersteigen. Das Papier untersucht deshalb folgende Fragestellung: Vergleichen Forschende die Ergebnisse der neuen ML Methoden transparent mit in den Wirtschaftswissenschaften etablierten traditionellen statistischen Modellen?
- Insgesamt 28% der prädiktiven ML Papiere geben keine Benchmark Performance von traditionellen statistischen Methoden an.
- Das Nicht-Reporting von traditionellen statistischen Methoden variiert je nach Disziplin, z.B. geben nur 6% der Studien aus Finance-Journals keine Benchmark-Performance traditioneller Modlele an, während es in Marketing-Journals 38% der ML Studien sind.
- Das Nicht-Reporting von traditionellen Benchmarkmodellen kann zum Teil durch die Verwendung von neuen Datensätzen zur Generierung von Vorhersagen erklärt werden (z.B. Text- oder Bilddaten)
(3) Wie viel besser performen ML Modelle als traditionelle statistische Methoden in der wirtschaftswissenschaftlichen Forschung und warum?
- Die meisten Studien reporten eine Outperformance des besten ML Modells gegenüber der besten traditionellen Benchmark. Eine Outperformance für das durchschnittliche reportete ML Modell wird jedoch nur in 69% aller Papiere erreicht.
- Das durchschnittliche ML Modells performt 65% weniger gut verglichen mit der Outperformance des besten ML Modells.
- Unsere Ergebnisse deuten darauf hin, dass Forschende einen hohen Aufwand betreiben müssen, um ein ML Modell zu finden, welches eine signifikante Outperformance gegenüber einer traditionellen Benchmarkmethode aufweist.
- Der Einsatz komplexer ML Modelle kann ineffizient sein, wenn die Forschungsfragen simple und die zugrundeliegenden Beziehungen zwischen den Variablen linear sind.
(4) Lohnt es sich, die Performance von neuen ML Modellen ehrlich und transparent mit der Performance traditioneller statistischer Verfahren zu vergleichen?
- Studien, die transparent eine Benchmarkperformance traditioneller Methoden reporten, erhalten im Durchschnitt drei Zitationen mehr pro Jahr als Studien, die keine Benchmarkperformance reporten.