Aug 28, 2022
When is a database beneficial to research groups?

Welcome to the second part of our database series. You can find the first part here.
What is an SQL database?
SQL is an established standard for databases. It is an abbreviation of Structured Query Language. This describes the query language used when working with a relational database. In a relational database, the data is stored in individual tables which all have a relational connection to each other.
Step 1: Create a database model
Before creating the database and filling it with data, it is important to perform a comprehensive data analysis to figure out how the database should be structured. The existing data is split up logically in tabular form, the columns are given appropriate names and clear (primary) keys for identification are assigned, which can then be used as foreign keys (reference) in other tables.
Example:
A Chair would like to create a systematic overview of its research projects. The projects – despite all of their differences – focus on investigating biological samples, which are stored in special cooling containers at different temperatures. To fulfill the legal archiving deadline and to store samples in an comprehensible manner for further research, all samples should be registered in a database. Data must be managed and brought in relation with each other: for instance on the origin of the sample, the storage location, the associated project, contacts and the temperature of the storage location.
The resulting data model, comprising the relations and the properties of the various entities to be managed, can also be illustrated in graph form:
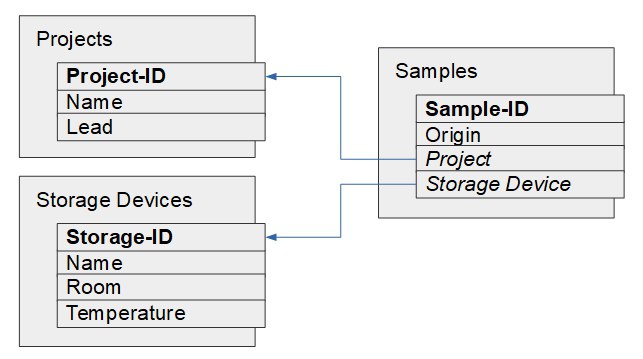
Graphical representation of the data model
In our example, three or for properties are stored for each type of entity.
Database and database querying
In order to illustrate the data model and associated work, we will continue with the example above and fill its tables with a few sample entries:
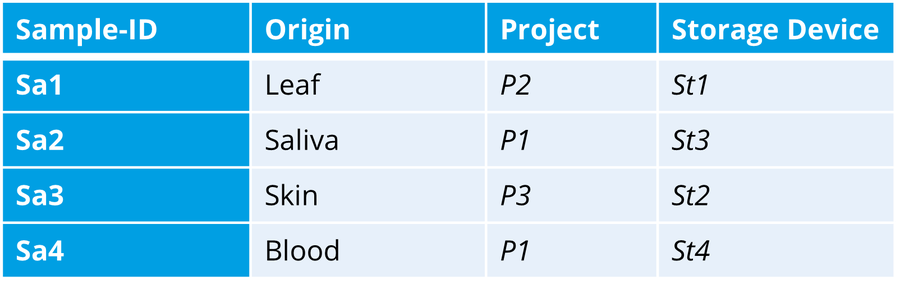
Samples
In the Samples table, the “Sample-ID” column serves as the primary key for the samples.
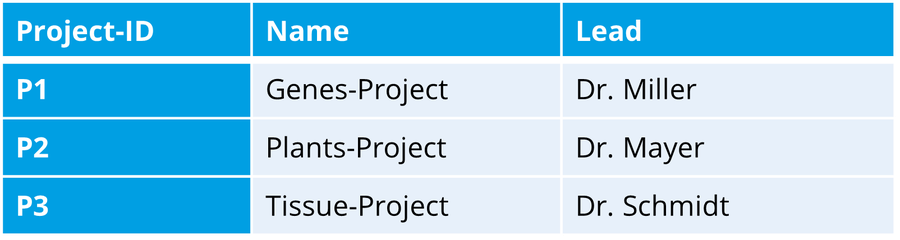
Projects
In addition, the datasets from this table reference the Projects table via the “Project” column. The “Project” column acts here as a foreign key, referring back to the primary key “Project-ID.”
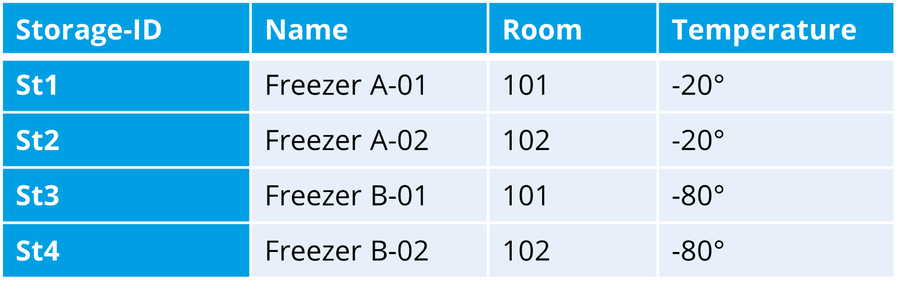
Storage
Similarly, the “Storage Device” column references the primary key “Storage-ID” in the Storage Devices table.
Members of the above-mentioned Chair can now start the following query: “Show me all blood samples from Dr. Miller’s projects and where they are stored.” Complex queries with information from the individual relational data tables are therefore possible.
What use do relational databases have in comparison to Excel?
This simple example alone shows the advantage relational databases have over a singular Excel spreadsheet. For any changes – for instance in temperature – only one entry needs to be modified in a relational database. Another advantage is that information on projects and storage locations can be reused and referenced by other tables (e.g. a table with publications).
The amount and complexity of data can quickly become too unwieldy for an Excel spreadsheet. Queries also tend to be better and faster via a database. Plus, Excel files can frequently only be edited locally and therefore need to be transferred manually between editors. Especially when there are many entries (for instance in the case of an institute with hundreds of employees working in very different fields of expertise and with various methods and data), a relational database can be particularly helpful.
If this brief insight has piqued your interest in databases, but you still aren’t sure if and how a database can benefit your group, send us an email via the Service Center Research Data. You can also book an advising appointment.