Objektbasierte Bestandsmodelle durch Multi-Daten-Fusion
Inhaltsverzeichnis
Projektdaten
| Titel | Title TP der TU Dresden im Verbundvorhaben mdfBIMplus: Teilautomatisierte Erstellung von objektbasierten Bestandsmodellen mittels Multi-Daten-Fusion multimodaler Datenströme und vorhandener Bestandsdaten | SP of TU Dresden in the joint research project mdfBIMplus: Partially automated creation of object-based inventory models using multi-data fusion of multimodal data streams and existing inventory data Förderer | Funding Bundesministerium für Digitales und Verkehr (BMDV) / mFUND Zeitraum | Period 12/2021 – 05/2025 Teilprojektleiter | Subproject manager Prof. Dr.-Ing. Steffen Marx Bearbeiterin | Contributor Mengyan Peng Projektpartner | Project partners Lehrstuhl und Institut für Baumanagement, Digitales Bauen und Robotik im Bauwesen (ICoM), RWTH Aachen University | Institut für Nachhaltige Technische Systeme (INATECH), Universität Freiburg | albert.ing GmbH, Frankfurt am Main | Galileo-IP GmbH, Altenstadt | customQuake GmbH, Hamburg |
Bericht aus dem Jahrbuch 2024/25
KI-basierte Teilplanerkennung von Brückenbestandsplänen
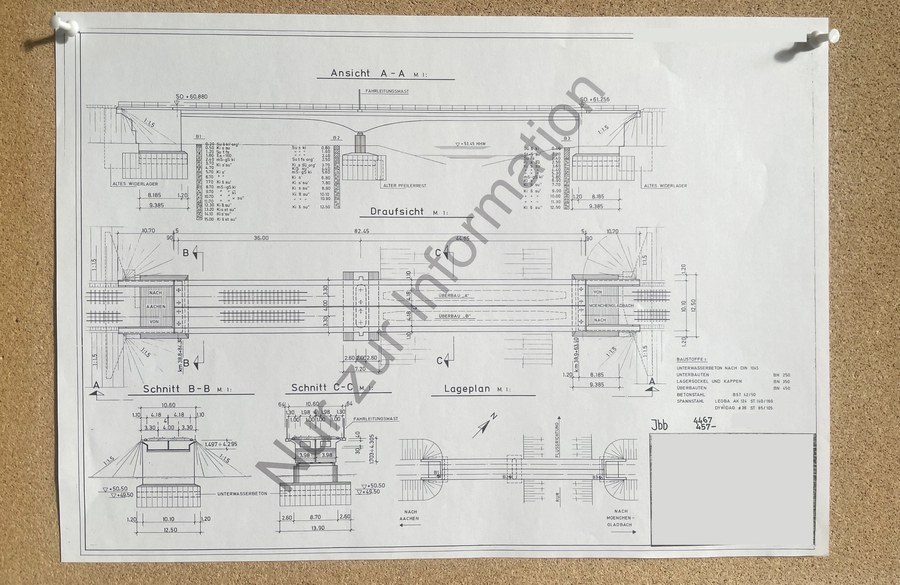
Herausforderung Teilplanerkennung in technischen Zeichnungen
Im Bauwesen verwenden technische Zeichnungen eine visuelle Sprache aus Linien, Symbolen und Anmerkungen, um bauliche Objekte darzustellen. Die Zeichnungen umfassen typischerweise Planköpfe, Bezugsraster, orthografische Ansichten, Schnittansichten, Bauhinweise usw. Tabellen enthalten Materialeigenschaften oder projektspezifische Daten. Ein wichtiger Schritt bei der automatisierten Analyse und Informationsgewinnung aus technischen Zeichnungen ist die Lokalisierung der verschiedenen Bestandteile. Insbesondere orthographische Ansichten und Schnitte, die sogenannten Teilpläne, sind zentrale Bestandteile. Daher ist die automatisierte Erkennung von Teilplänen ein lohnenswertes Forschungsthema.
Die Objekterkennung bietet großes Potenzial für die Anwendung bei technischen Zeichnungen und bei der Erkennung von Teilplänen. Sie ist ein Teilgebiet der Bildverarbeitung und des computergestützten Sehens, das darauf abzielt, Objekte in Bildern zu identifizieren. Dazu werden Bilder in sinnvolle Regionen unterteilt, die anschließend anhand ihrer Merkmale analysiert und einer Objektklasse zugeordnet werden. Häufig eingesetzte Verfahren sind Kantenerkennung, Transformationen sowie Größen- und Farberkennung. Komplexere Ansätze stammen aus der künstlichen Intelligenz, insbesondere maschinelles Lernen und Deep-Learning-Modelle, die eine besonders hohe Leistungsfähigkeit haben.
Aufgrund von Unterschieden bei den Eigentumsverhältnissen und den erstellenden Ingenieurbüros, den Erstellungszeitpunkten und bei Qualitätsstandards gibt es erhebliche Variationen in der Anordnung der Teilpläne innerhalb einer Zeichnung. Diese Inkonsistenzen machen den Einsatz traditioneller Programmieransätze schwierig, weshalb flexible und KI-basierte Methoden bevorzugt werden. Daher wurde ein spezifischer Trainingsdatensatz für die Teilplanerkennung erstellt, mit dem typische KI-Modelle der Objekterkennung wie SSD, YOLOv7 und CO-DETR trainiert wurden. Alle Modelle zeigten vielversprechende Trainingsergebnisse, was die Machbarkeit der Anwendung von Objekterkennungstechnologien für die Teilplanerkennung in technischen Zeichnungen bestätigt.
Bericht aus dem Jahrbuch 2023
KI-basierte Informationsextraktion von Brückenbestandsplänen

Beispiel für die teilautomatisierte Extraktion der Zeichnungsnamen
Technische Zeichnungen im Bauwesen bedienen sich einer visuellen Sprache aus Linien, Symbolen und Annotationen, um Objekte für die Konstruktion darzustellen. Typischerweise umfassen diese Pläne Planköpfe, Bezugsraster, orthografische Ansichten, Schnittansichten, Bauhinweise usw. Zusätzlich können Tabellen eingefügt sein, um Materialeigenschaften oder projektspezifische Daten bereitzustellen. Obwohl diese Pläne im Allgemeinen einer gemeinsamen Struktur folgen, variieren sie aufgrund von Eigentümerverhältnissen, Ingenieurbüros, Erstellungsjahren und Qualitätsunterschieden, wobei ältere Pläne möglicherweise handschriftlichen Text enthalten. Aufgrund dieser Inkonsistenzen sind herkömmliche Programmieransätze unpraktisch. Daher wird ein flexibler, KI-basierter Ansatz bevorzugt.
Durch die Kombination eines Optical Character Recognition Algorithm (OCR-Algorithmus) mit eigens entwickelten Nachbearbeitungsalgorithmen ist es möglich, spezifische Informationen zu Bauteilen und deren Eigenschaften zu extrahieren. OCR-Algorithmen erzeugen typischerweise Ausgaben, die sowohl Text als auch zugehörige Koordinaten enthalten. Die Nachbearbeitung umfasst das Nachzeichnen des Textes anhand dieser Koordinaten, wobei verschiedene Nachzeichnungsmethoden je nach Merkmalen der Textkomponenten verwendet werden. Nach einer Vergleichsstudie verschiedener OCR-Algorithmen wird der Handprint für die Texterkennung ausgewählt.
Für die Extraktion von Informationen aus Planköpfen (z. B. Zeichnungsnamen) wird die Nachzeichnungsmethode mit der Definition des Koordinatenbereichs verwendet. Dies ist möglich, weil Planköpfe in der Regel in der unteren rechten Ecke des Rasters platziert sind, was die Festlegung von Standortregeln ermöglicht. Um Baustoffinformationen aus Plänen zu extrahieren, wird die Nachzeichnungsmethode mit der Definition von Schlüsselwörtern eingesetzt. Dies basiert auf dem Vorhandensein bestimmter Zeichenketten wie „Baustoffe“, die offensichtlich mit Baustoffinformationen verbunden sind. Die extrahierten Baustoffinformationen können in BIM-Modelle oder digitale Zwillinge integriert werden, basierend auf den extrahierten Zeichnungsnamen. Dies trägt zur semantischen Verbesserung der Modelle bei.
Bericht aus dem Jahrbuch 2022
Automatische Texterkennung in Bestandsplänen von Brücken

Beispiel für die automatisierte Texterkennung eines Schnittes
In Deutschland gibt es über 65.000 Brücken in der Verkehrsinfrastruktur. Für die meisten von ihnen existieren keine editierbaren 2D-Pläne, was dazu führt, dass Textinformationen, z. B. für BIM-Modelle, manuell gesucht werden müssen. Für große Sanierungs- oder Ersatzneubauvorhaben ist dieses Verfahren sehr zeit- sowie arbeitsintensiv. Mit einer automatischen Texterkennung, welche im Rahmen des mdfBIMplus-Forschungsprojekts entsteht, soll die Auswertung von Bestandsplänen deutlich vereinfacht werden.
Die Methode der automatischen Texterkennung basiert auf der optischen Zeichenerkennung (OCR), welche mithilfe neuronaler Netztechnik schrittweise verbessert wird. Dadurch können auch gesamte Zeilen eines Textes verarbeitet werden. Erschwert wird die automatische Texterkennung maßgeblich durch verschiedene handschriftliche Ergänzungen auf Bestandsplänen sowie deren unterschiedliche Layouts. Dazu existieren in öffentlichen Quellen, wie Github, verschiedene OCR-Algorithmen mit Handschrift- und Layouterkennungsfunktion. Diese Möglichkeiten zur Texterkennung werden analysiert und anhand von Textfragmenten aus 2D-Brückenplänen bewertet.
Basierend auf diesen Ergebnissen werden neun Algorithmen ausgewählt: tesseract-ocr, pytesseract, easyocr, keras-ocr, OCRmypdf, PaddleOCR, ocr-Chinese, Handprint und Handwriting-ocr. Die ersten fünf zählen zu den klassischen Methoden im Bereich der Texterkennung und sind darüber hinaus sehr benutzerfreundlich. PaddleOCR und ocr-Chinese sind vergleichsweise weniger umfangreich und müssen daher mit einem Textrainingssatz aus Plänen vervollständigt werden. Sie sind jedoch in der Lage, das Layout der jeweiligen Pläne zu erkennen. Handprint und Handwriting-ocr können bereits ohne vorheriges Training zur Handschriftenerkennung eingesetzt werden.
Im nächsten Schritt werden die neun Algorithmen getestet. Daraus können die Methoden abgeleitet werden, welche sich am besten zur Texterkennung eignen. Das Ziel besteht darin, eine automatische Suche mit einer Extraktion der benötigten Textinformationen aus 2D-Brückenplänen zu ermöglichen.
Bericht aus dem Jahrbuch 2021
Vom Papierplan zum BIM-Modell

Laserscanning mit Drohnen
In Deutschland gibt es über 65.000 Brücken der Verkehrsinfrastruktur, für dessen Großteil keine digitalen Modelle existieren. Digitale 3D-Modelle des Bestands sind jedoch für eine prädiktive Instandhaltung eine grundlegende Voraussetzung. Darüber hinaus sind die vorhandenen, sehr heterogenen Pläne häufig historisch, unvollständig oder lückenhaft. Um dem enormen Bedarf an Sanierungen oder Ersatzneubauten gerecht zu werden, sind daher aussagekräftige und genaue Bestandsunterlagen notwendig. Abhilfe kann hier die prozessuale Entwicklung von Verfahren und Systemen im Zuge des Forschungsprojektes mdfBIM+ schaffen.
Kernziel des Projektes ist die (teil-)automatisierte Erstellung von georeferenzierten, objektbasierten Geometriemodellen von bestehenden Brückenbauwerken. Die (teil-)automatisierte Modellerstellung wird auf Basis der Verknüpfung von aktuellen Messdaten (Photogrammetrie- bzw. LiDAR-Aufnahmen) mit allen vorhandenen heterogenen Bestandsdaten einer Brücke realisiert. Im Projekt erfolgt dies prototypisch für Brücken, lässt sich aber auf Strecken und weitere Bauwerke übertragen.
Durch Multi-Sensor-Aufnahmen wird eine kombinierte und homogenisierte Punktwolke für Infrastrukturbauwerke erstellt und durch KI-basierte Analysemethoden semantisiert. Die vorhandenen Bestandsunterlagen werden geclustert und teilautomatisiert analysiert, um definierte Parameter zu extrahieren. In Kombination mit der homogenisierten Punktwolke kann darauf aufbauend das digitale Bestandsmodell modelliert werden, welches im Anschluss mit allen relevanten Informationen attribuiert wird.
Wesentliche Erkenntnisse über die Machbarkeit von Teilautomatisierungen in der Prozesskette konnten bereits im Rahmen der Vorstudie mdfBIM nachgewiesen werden. Diese Prozesse werden nun vollumfänglicher betrachtet, sodass im Ergebnis eine prototypische Prozessdarstellung inklusive softwareseitiger Umsetzung steht. Dieses Ergebnis kann anschließend für weitere Bauwerke sowie Streckenabschnitte der Verkehrsinfrastruktur übernommen werden und damit einen wesentlichen Beitrag zur Digitalisierung leisten.