Object-based inventory models through multi-data fusion
Table of contents
Project data
| Titel | Title TP der TU Dresden im Verbundvorhaben mdfBIMplus: Teilautomatisierte Erstellung von objektbasierten Bestandsmodellen mittels Multi-Daten-Fusion multimodaler Datenströme und vorhandener Bestandsdaten | SP of TU Dresden in the joint research project mdfBIMplus: Partially automated creation of object-based inventory models using multi-data fusion of multimodal data streams and existing inventory data Förderer | Funding Bundesministerium für Digitales und Verkehr (BMDV) / mFUND Zeitraum | Period 12/2021 – 05/2025 Teilprojektleiter | Subproject manager Prof. Dr.-Ing. Steffen Marx Bearbeiterin | Contributor Mengyan Peng Projektpartner | Project partners Lehrstuhl und Institut für Baumanagement, Digitales Bauen und Robotik im Bauwesen (ICoM), RWTH Aachen University | Institut für Nachhaltige Technische Systeme (INATECH), Universität Freiburg | albert.ing GmbH, Frankfurt am Main | Galileo-IP GmbH, Altenstadt | customQuake GmbH, Hamburg |
Report from year book 2024/25
AI-based sub-plan recognition of as-built bridge plans
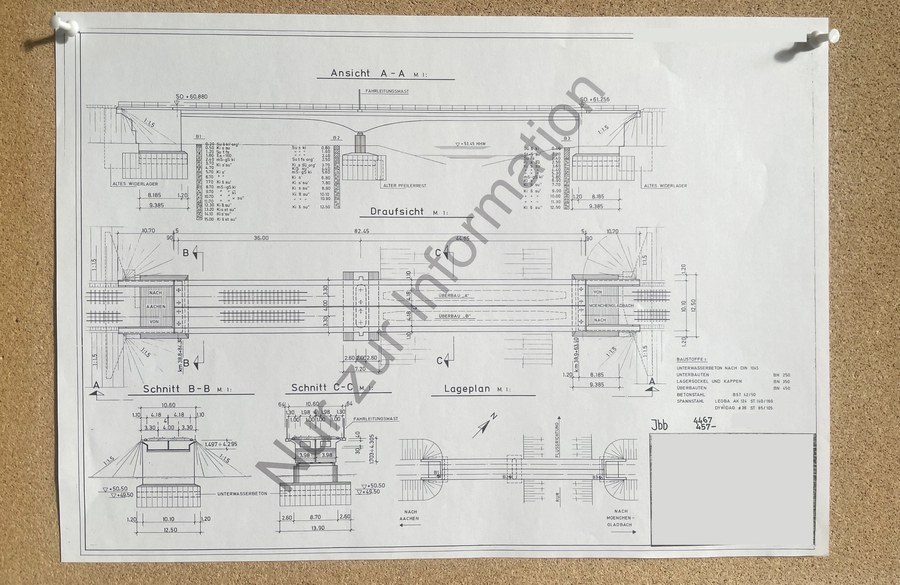
Challenge sub-plan recognition in technical drawings
In civil engineering, technical drawings serve to represent structural objects in a detailed and precise manner. They employ a visual language of lines, symbols, and annotations and typically include title blocks, reference grids, orthographic views, sectional views, and construction notes. Additionally, tables may be incorporated to provide material properties or project-specific data. A crucial step in the automated analysis of such drawings is the localization of their various components. Among these, orthographic and sectional views, known as “sub-plans,” play a particularly important role. Consequently, the automated recognition of sub-plans represents a significant and forward-looking research topic.
To address this challenge, object recognition offers substantial potential, particularly in the context of sub-plan recognition. Object recognition, a subfield of image processing and computer vision, aims to identify objects in images based on their features. This process involves dividing an image into meaningful regions, which are then analyzed and assigned to specific object classes. Established methods in image processing include edge detection, transformations, and size and color recognition. More advanced approaches leverage artificial intelligence, particularly machine learning and deep learning techniques, which excel in performance and adaptability.
Due to the diversity in ownership, engineering firms, creation dates, and quality standards, the layouts of sub-plans in technical drawings vary significantly. These inconsistencies hinder the applicability of traditional programming methods, making flexible, AI-based approaches preferable. In this context, a specific training dataset for sub-plan recognition was developed, and leading object recognition models such as SSD, YOLOv7, and CO-DETR were trained using this dataset. The models demonstrated excellent training results, confirming the feasibility and value of applying object recognition technologies to sub-plan recognition in technical drawings.
Report from year book 2023
AI-based extraction of information in existing bridge plans

Beispiel für die teilautomatisierte Extraktion der Zeichnungsnamen
Technical drawings in civil engineering employ a visual language consisting of lines, symbols, and annotations to represent objects intended for construction. These drawings typically encompass title blocks, reference grids, orthographic views, section views, detail views, and construction notes. Additionally, tables may be included to provide material properties or project-specific data. While these plans generally adhere to a common structure, variations exist based on the owner, engineering firm, creation year, and quality, with older plans possibly featuring handwritten text. Due to this inconsistency, conventional programming methods are impractical, and a flexible machine learning-based approach is preferable.
By combining the use of an optical character recognition (OCR) algorithm with self-developed post-processing algorithms, it is possible to extract specific information about different building components and their properties. OCR algorithms typically produce output comprising both text and associated coordinates. Post-processing involves retracing the text using these coordinates, with different tracing methods employed based on the features of the text components. Following a comparative assessment of various OCR algorithms, the Handprint OCR algorithm is selected for text recognition.
For extracting information from title blocks (e.g., drawing names), the tracing method with the definition of the coordinate region is utilized. This is because title blocks are typically situated in the lower right-hand corner of the grid, allowing for location rules to be established. To extract material information from construction annotations, the tracing method with the definition of the keyword is applied. This is based on the presence of specific character strings such as “material,” “instruction,” etc., which are evidently associated with material information. The extracted material information can be integrated into BIM-models or digital twins based on the extracted drawing names. This contributes to the efficient semantic enhancement of the models.
Report from year book 2022
Automatic text recognition of bridge plans

Example of the automated text recognition of a cross-section
In Germany, there are over 65,000 bridges in the transport infrastructure. For the majority of which there are no editable 2D plans. This means that if certain text information from 2D plans is required, e.g., for the purpose of semantically enriching a BIM model, you have to search and find it manually with your eyes. However, the manual implementation of such search functions for 2D plans is too time-consuming and labor-intensive when there is an enormous need for renovations or new replacement of bridges. The automatic text recognition in the course of the mdfBIMplus research project can help here.
The examined method of automatic text recognition of 2D bridge plans is based on optical character recognition (OCR). This technique tends to be improved with the development of the neural network technique for processing the whole rows of the texts.
The two major difficulties in the automatic text recognition of 2D bridge plans are the varied handwritten fonts and complicated layouts of the text in plans. The solutions for this are researching some OCR algorithms with handwritten recognition and layout recognition capabilities in open sources. In addition, the performances of the OCR algorithm candidates from open sources are evaluated using fragments of the texts from 2D bridge plans.
Based on the results of the algorithm research, 9 algorithms were decided. They are: tesseract-ocr, pytesseract, easyocr, keras-ocr, OCRmypdf; Paddleocr, ocr-Chinese, Handprint and Handwriting-ocr. The first five algorithms are fairly classic in the field of text recognition and are extremely user-friendly. Paddleocr and ocr-Chinese are less pretrained. In order to strive for perfect performance, both need training with the text training set from plans. However, they are capable of layout recognition. Handprint and Handwriting-ocr are absolutely pretrained and professional in handwriting recognition.
The future step is to test the 9 algorithms. After testing, the most appropriate text recognition algorithms for 2D bridge plans can be determined. In the end, the automatic search and extraction of the required text information from 2D bridge plans will be feasible.
Report from year book 2021
From blueprints to a BIM model

Laser scanning with drones
There are over 65,000 bridges in the transport infrastructure in Germany and for the majority of which no digital models exist. However, 3D models of the existing structures are a fundamental requirement for predictive maintenance. In addition, the existing very heterogeneous plans are often historical, incomplete or sketchy. Therefore, the need for meaningful and precise as-built documents for the renovations or replacements of new structures is not fully met. This can be remedied by the procedural development of processes and systems in the course of the mdfBIM+ research project.
The main objective of the project is the (partially) automated creation of georeferenced, object-based geometry models of existing bridge structures. The (partially) automated model creation is realized on the basis of linking current measurement data (photogrammetry or LiDAR recordings) with all existing heterogeneous data of a bridge. In the project, this is done as a prototype for bridges, but can be transferred to roadways and other structures.
A combined and homogenized point cloud for infrastructure structures is created using multi-sensor recordings and semanticized using AI-based analysis methods. The existing as-built documents are clustered and analyzed in a semi-automated manner in order to extract defined parameters. In combination with the homogenized point cloud, the digital as-built model can be modelled on this basis, which is then attributed to all relevant information.
Essential findings about the feasibility of partial automation in the process chain have already been demonstrated in the mdfBIM preliminary study. These processes are now considered more comprehensively so that the result is a prototypical process representation including software implementation. This result can then be used for other structures and roadways sections of the transport infrastructure and thus make a significant contribution to digitalization.