Research
We study how the genome encodes different layers of information, specifically its own stability, repair, and mutagenesis. Using a combination of computational biology, machine learning, deep learning models for sequence data, clinical and experimental data from collaborating labs, we try to understand the underlying mechanisms despite their complexity, and look for routes to bring this knowledge into clinical use.
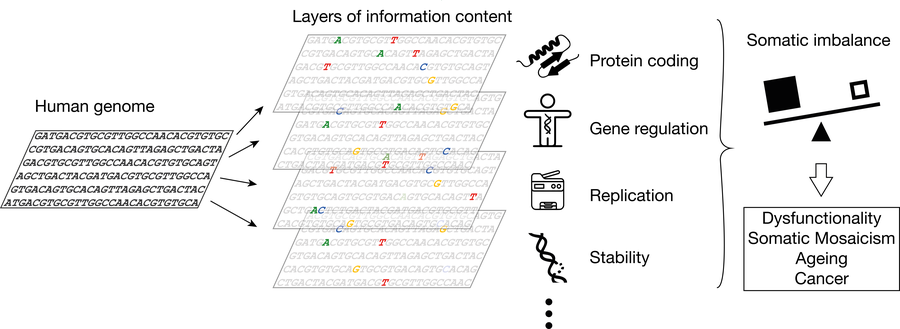
The genome encodes for genes that are translated into proteins. Specific sequence patterns are also encoding a regulatory framework for genes to be expressed context-specifically and in the tissues they are needed in. Evolution has formed the underlying DNA sequence in balance with the sequence necessary for successful genome replication and keeping it sufficiently stable. When these layers of code get out of balance in the soma, it may lead to dysfunctionality, increased instability and mutagenesis, and consequently somatic mosaicism, ageing and cancer development.
To understand these processes, we are making use of the large amounts of data available to us in the form of sequenced cancer and other somatic genomes, genome-wide DNA damage measurements, epigenetic data, data to investigate 3D genome architecture, and the genome sequence itself.
Using computational biology, machine learning, and DNA language models (DLMs), we aim to understand how genomes encode different layers of information, how the layers function in interaction, and specifically how processes of DNA damage susceptibility, repair, and mutagenesis are dependent on DNA sequence in interaction with other genome biology.
We work with four major focus areas:
1. Learning DNA sequence dependence of genome biology with large language models on genome data
The genetic code is frequently viewed from the perspective of how proteins are encoded in the DNA. Yet, also the probability to mutate, the stability of the double helix, the ability to form non-B-DNA, and the location of repetitive sequence, the possibility to be epigenetically marked, is to some extent also encoded in the DNA, we just don't understand it.
We are trying to tackle this with the help of large language models that also in linguistics now give unprecedented possibilities to quantitatively describe grammar, semantics and other language rules. Why not using DNA as a text and do the same? In addition to a basic understanding of how the language of DNA works beyond protein coding, using language models for targeted machine learning tasks show much increased performance and can be used for example to model mutation rate distributions, define genome elements, or derive probabilities of DNA breakage. They also allow to extract information on how and why the models learn, and where the limits of DNA sequence contribution might be.
2. The genomics of DNA damage, repair, and DNA damage response
This area combines several projects that we pursue together with collaborators on mechanistic questions in the DNA damage response. Combining biochemical data with functional genomics approaches, machine learning, and DNA language models, these highly interdisciplinary projects address a variety of mechanistic questions that currently occupy the field. We are specifically interested in genome instability represented by 8-oxo-guanine, DNA-incorporated uracil, apurinic sites, which we can measure with AP-Seq, the method we developped. Distribution of these DNA damage types is very heterogenous over the genome. The associated mechanisms are very poorly understood. Are we maybe even mistaking oxidative DNA "damage" as something entirely unwanted? Could there be a second side to the coin, a function as a stress sensor, a role as an epigenetic mark?
3. The genomics of mutagenesis and somatic genome evolution
We are using machine learning and deep learning approaches to learn from somatic sequencing data, how, where, and why somatic tissues and tumours accumulate mutations. These mutations are then exposed to selective pressures and can drive the development of somatic mosaicism, clonal hematopoiesis, many ageing phenotypes, and cancer development. By understanding the rules of mutation accumulation in the first place, we hope to contribute to the quantification of somatic evolutionary driving forces for those phenotypes. This allows us to bring our findings to clinical application and is aimed to be developped into increasingly accurate (somatic) genotype - phenotype predictions.
4. Collaborative data science
The principles behind or approaches to investigate genome sequence are applicable to a variety of questions, including clinical predictions based on omics data, investigations of gene regulatory networks, gene regulation via 3D genome architecture, and other interesting genome biology that show complex regulation via the DNA sequence. These questions have large potential for a wider use of our DNA language models. Therefore, we collaborate on a selection of projects with experiemental and clinical partners, as well as larger consortia.
Specific current interest areas are:







Methodological and Technical Expertise
- Functional genomics (multi-omics in bulk and single cell; wet and dry)
- X-Seq data analysis, including (sc)RNA-Seq, ChIP-Seq, ATAC-Seq, DRIP-Seq, iCLIP, CAGE-Seq, END-Seq, HiC,...
- Oxidative DNA damage genome-wide measurements and data analysis
- Cancer genomics
- Genome editing data analysis
- Machine Learning
- Clinical Outcome Predictions (with machine learning)
- Deep Learning
- Natural Language Processing (on genomes)